最新AI「ミュトス」を使えても「バグマゲドン」に? Firefox開発元に学ぶセキュリティ対策
小林啓倫のエマージング・テクノロジー論考
4月、Webブラウザ「Firefox」を手掛ける米Mozillaが驚くべき成果を発表した。Firefoxの新バージョン「Firefox 150」において、271件の脆弱(ぜいじゃく)性を一気に発見し、修正したというのだ。
立役者となったのが、米Anthropicが同月7日に発表した最先端のAIモデル(フロンティアモデル)「Claude Mythos Preview」(以下、Mythos)だ。「神話(Mythos)」の名を持つこのモデルを活用し、Mozillaはこれまでになかったほど大量の脆弱性を発見できた。
Mozillaは、271件の脆弱性のうち、180件を最高レベルのsec-high(通常のWeb閲覧をしているだけでも発生してしまうほどの深刻度)、80件をsec-moderate、11件をsec-lowに分類する。
なかには15~20年間も隠れていたバグもあり、いずれも長年のファジング(ソフトウェアに大量の異常入力を与えて不具合や脆弱性を見つける自動テスト手法)と人間による監査をすり抜けてきたものだった。同月にMozillaが修正した脆弱性は計423件に達し、同社の2025年の月間平均修正件数を約14倍上回った。
MozillaのCTOであるBobby Holley氏は公式ブログで、最初の発見結果を見たときの感覚を「めまいを覚えた」と表現している。
「ハードニング済みのターゲット(後述する『多層防御アーキテクチャ』や継続的な脆弱性対応の積み重ねで、新たな攻撃経路を見つけにくい状態まで防御が強化されたソフトウェアを指す)なら、2025年であれば、こんなバグが1つ見つかっただけで赤色の警報レベルだった」(Holley氏)
この数字を受けて、業界には1つの“神話”が流れ始めている。それは「Mythosのような先端AIモデルのアクセス権さえ手に入れば安心」というものだ。これだけ大量の脆弱性を一気に発見できるようになったのは、ひとえにMythosの力であり、その力を手に入れられれば自社でも同じ対応が可能になる、というわけだ。
しかしMozillaが26年5月7日に公開した詳細なレポートを読み込むと、この物語が半分しか正しくないことが分かる。Mythosにアクセスできる組織は他にも多数存在するが、Firefox 150のような規模で修正できた例は、現時点では確認できていない。
サイバーセキュリティ専門メディアの「The Hacker News」は、Anthropicが一部企業にMythosを提供しながら進めるセキュリティ強化の取り組み「Project Glasswing」で発見された脆弱性のうち、実際にパッチが出たのは1%未満と指摘している。発見のフェーズはAIで爆発的にスケールしたが、修正フェーズでスケールできた組織はほとんどなかったわけだ。
なぜMozillaだけがそれを可能にしたのか。この記事では、Mozillaのレポートを読み解き、彼らの対応能力を「フロンティアAIモデル」「ハーネス」「パイプライン」の3層に分けて考えた上で、「自社でもMythos級のフロンティアAIモデルが利用できるようになる」時代に向けて、何を準備すべきかを考察してみたい。
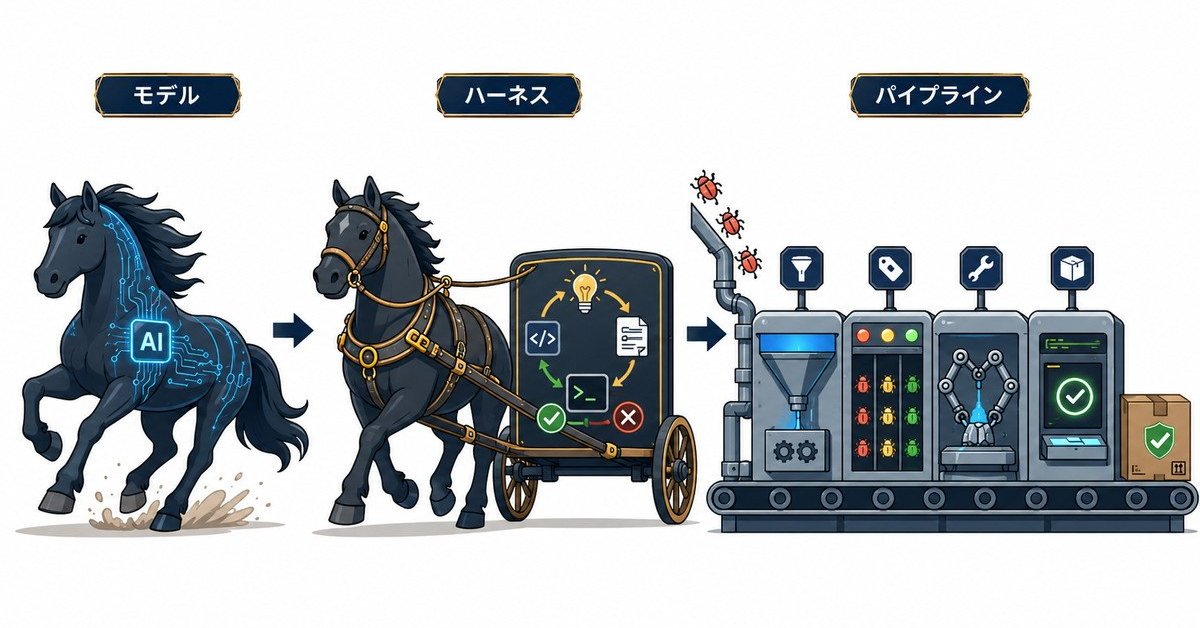
Mozillaのレポートは「Claude Mythos Previewを活用したFirefoxセキュリティ強化の舞台裏」と題されている。執筆したのは、Mozillaのセキュリティやプラットフォーム基盤を担う3人の中心的エンジニア。彼らは同レポートで、AIによる脆弱性発見を支える要素を、次の3層に分けて記述している。
第1層は、推論能力そのものを提供するフロンティアAIモデル。Claude Mythos Previewのほか、AnthropicのAIモデル「Claude Opus 4.6」や米OpenAIの「GPT-5」などが該当する。
Copyright © ITmedia, Inc. All Rights Reserved.
生成AIやメタバース、新たなサイバー攻撃など、テクノロジーの進化が止まらない。少しずつ生活の中に浸透し、その恩恵を預かれることもある一方、思いもよらない問題を生み出すこともある。このコーナーでは、さまざまな分野の新興技術「エマージング・テクノロジー」について、小林啓倫氏が解説する。
この連載の記事をもっと見るPage 2
小林啓倫のエマージング・テクノロジー論考
第2層は、第1層にあるモデルを駆動して、「コードに対する仮説を立て、再現可能なテストケースを書き、動的に検証する」ループを回す「ハーネス」。Mozillaは「適切なインタフェースと指示が与えられれば、ハーネスはコード内のバグに関する仮説を動的に検証するための、再現可能なテストケースを生成・実行できる」と説明する。
第3層は、ハーネスが吐き出すバグ候補を、最終的な対応完了にまで導く「パイプライン」。パイプラインは(a)既知バグとの重複排除、(b)優先度のトリアージ、(c)修正の実装、(d)テスト、(e)リリース、というステップで構成される。Mozillaは「発見系のサブシステムだけでは、必要条件を満たしたにすぎない」として、この一連の運用基盤こそがスケールの鍵だと明示している。
決定的に重要なのは、3つの層は「各社で再現できる難易度」が大きく異なる点だ。Mozillaは「ハーネスはプロジェクト間で横展開可能だが、パイプラインは本質的にプロジェクト固有のものだ」と説明する。
確かにフロンティアAIモデルは、発表当初は限られた企業・組織しか手にできないことが多いが、そうした制約は技術とは違う領域(政治や経済など)で生まれる。その意味でフロンティアAIモデルは、「API経由で誰でも入手できる」ものとして位置付けることができる。ハーネスも技術さえあればどんな企業でも開発できる。
しかしパイプラインだけは、各組織のコードベース、ツールチェーン、組織運用に深く根を張った固有の資産だ。簡単にまねしたり、移植したりできる類のものではない。
この3層構造と、それぞれの役割を理解することが、Mozillaの成功を読み解く鍵となる。MozillaがMythosで成果を出せた本当の理由は、最上層のモデルでも中間層のハーネスでもなく、最下層のパイプラインに長年投資してきたことにある。
各階層の詳細を順に見ていこう。
最上層のフロンティアAIモデルは、半年程度のスパンで急速にコモディティ化が進む方向にある。英国の研究機関AI Security Institute(AISI)は、Mythosが「過去のフロンティアモデルから一段階の進化を示した」と評価しつつ、サイバー能力の急速な向上はMythos単独の現象ではなく、フロンティアAI業界全体で並行して進んでいる点を強調する。
AISIによれば、Mythosは32ステップから成る企業ネットワーク侵入シミュレーション「The Last Ones」を史上初めて完走し、Mythosの新しい版(さらに学習を進めたもの)では10回中6回成功した。OpenAIのAIモデル「GPT-5.5」も同シミュレーションを10回中3回クリアしており、AISIは「自律的に多段サイバー攻撃を実行できる」段階にこの2モデルが到達したと整理する。
米Googleでも、「Big Sleep」という、同社のAIモデル「Gemini」ベースのAIエージェントに人間のセキュリティリサーチャーの作業手順を模倣させ、過去バグの類似パターンを起点にコードを監査する仕組みが実世界の脆弱性を複数発見し、継続的な成果を上げている。フロンティアAIモデルを提供できる企業の数は、ますます増えていく可能性が高い。
一方、第1層にはわなが潜んでいる。「フロンティアAIモデルさえ手に入れられれば、あとは自動的に脆弱性が見つかり、修正される」という思い込みだ。ここでは、このわなを「モデル幻想」と呼んでみたい。
この幻想がいかに脆いかは、25~26年初頭のオープンソースコミュニティーの動向が雄弁に物語っている。代表的な例が、オープンソース開発プロジェクトの一つである、curlプロジェクトのバグバウンティ(バグ発見に報奨金を支払うプログラム)閉鎖だ。
curl開発者のDaniel Stenberg氏は、AIで生成された低品質な「脆弱性報告」が大量に寄せられ、メンテナの限られた時間を浪費している状況を「死に至る千の汚泥」と表現し、26年1月末をもってバグバウンティを停止した。半年前の25年中旬時点のデータでは、curlに届く報告のうち真に脆弱性を指摘していたのは約5%、AI生成と疑われるものが約20%だったという。
高度なAIモデルが社会に普及した結果、「脆弱性を発見したように見える出力」を誰でも安価に生成できるようになった。そうした出力は、単体ではバグレポートにならない。再現可能なテストケース、つまり受け止め側で検証できる仕組みがなければ、出力は単なるノイズに転落する。
実はMozillaも、Anthropicから26年2月に最初のFirefoxバグ報告を受け取った際、AIスロップ(AIが大量生成する、もっともらしく見えるが内容の乏しい低品質コンテンツの総称)を警戒していた節がある。
ただMozillaの公式ブログでは、Anthropic側の報告を確認したところ、「最小化されたテストケースが添付されており、セキュリティチームが各問題を迅速に検証・再現できた」として、そのクオリティーを評価している。逆に言えば、そうした補足情報のない報告はMozillaにとっても「さばけない」のだ。
モデル幻想を回避するために必要なのは、モデル単体ではなく、モデルが吐く仮説をその場で検証する仕組み――次に述べる第2層、ハーネスだ。
Mozillaは、前世代のAIモデル「Claude 3.5 Sonnet」や「GPT-4」を用いた静的なコード解析実験では、各モデルが「いくらかの有望さは示したが、偽陽性率の高さからスケールが不可能だった」と説明する。コードを読ませて「脆弱性らしきもの」を列挙させるだけのアプローチでは、社内のセキュリティチームが受け止め側として疲弊するだけで、curlコミュニティーが外部から味わったのと同じ消耗を内部で繰り返すことになる。
Copyright © ITmedia, Inc. All Rights Reserved.
生成AIやメタバース、新たなサイバー攻撃など、テクノロジーの進化が止まらない。少しずつ生活の中に浸透し、その恩恵を預かれることもある一方、思いもよらない問題を生み出すこともある。このコーナーでは、さまざまな分野の新興技術「エマージング・テクノロジー」について、小林啓倫氏が解説する。
この連載の記事をもっと見る